Substage update: Bring Your Own AI & One-off purchase out now!

25th March 2025
Good news! Substage now supports custom API keys and local LLM models, and a one-off purchase option is out now, if you want to Bring Your Own AI! That means you can:
- Use your own API key for OpenAI, Anthropic, Google or Mistral
- Run local LLMs via LM Studio or Ollama — right on your own machine
The one-off purchase option is only available in the latest version of Substage, so be sure to grab the update if you decide to pick it up!
Also, in this new version: I'm re-enabling support for Google Gemini. I was previously uncomfortable with their privacy stance, as it varied depending on payment tier. After reviewing it more carefully and ensuring everything was properly configured on my end, I'm comfortable re-including it. Additionally, with users now able to use their own API keys, I wanted to ensure I was meeting people where they were at.
If you already have a previous version of Substage installed, click its icon in the menu bar and choose Check For Updates. Otherwise, download the latest version here!
I’ve also set up a brand new Discord server. If you’ve got questions, ideas, or want to share what models are working well for you, that’s the place!
How to get started
Using your own API key
Click the Substage settings button, head to the new AI Models tab, pick a model (like GPT-4o), and paste in your API key. That key is saved for the provider, so if you later pick another OpenAI model—like GPT-4o-mini—it’ll use the same one.
By the way, if you haven't tried Mistral yet, I can highly recommend them - their models are really fast and accurate.
Running a local LLM
You’ll need either LM Studio or Ollama. If you haven’t used either, LM Studio is probably the easier way in — it’s got a solid UI and good setup defaults.
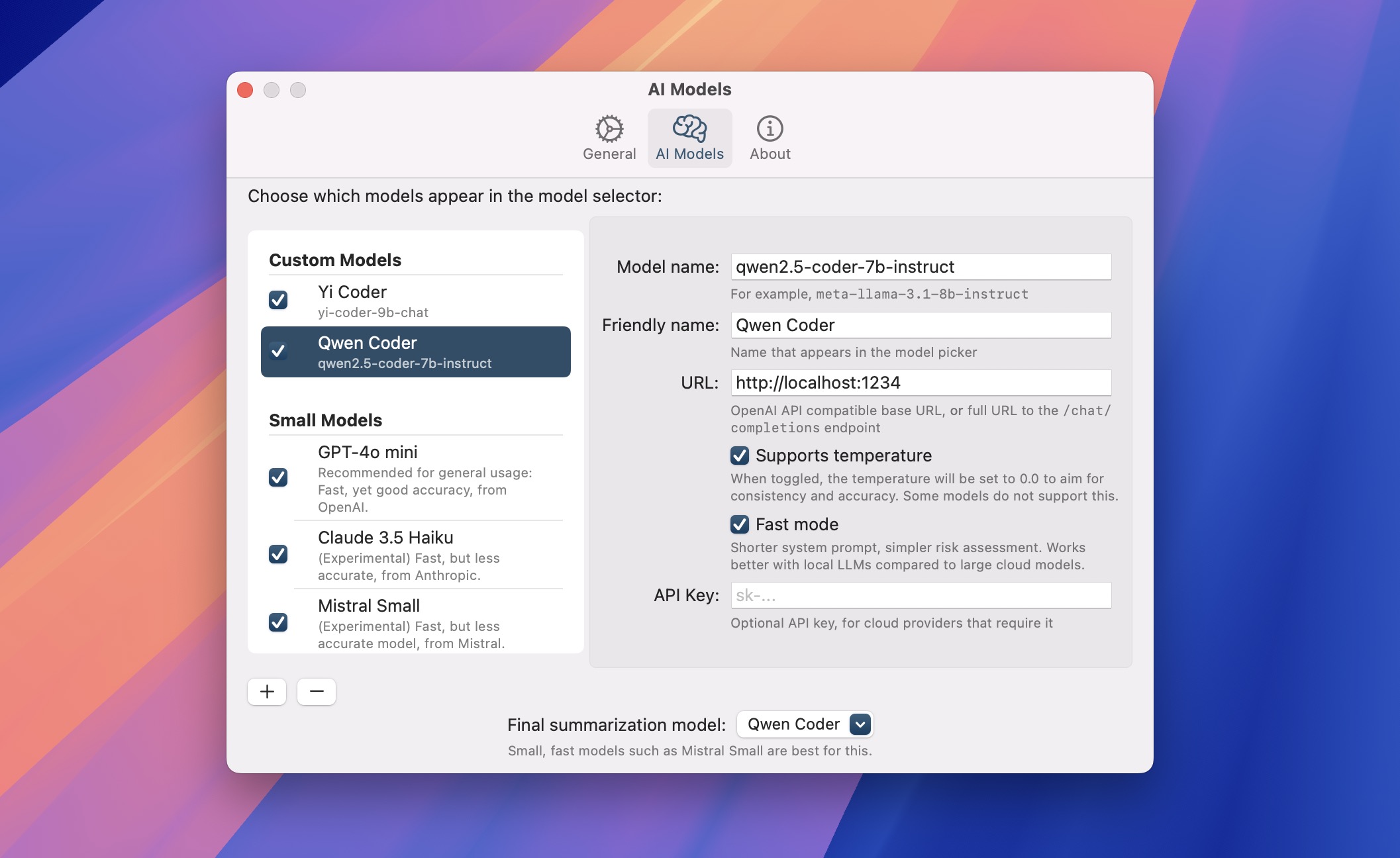
Once it’s running and you've got a model downloaded, click Substage's Settings button, and browse to the AI Models tab. Click the "+" button and selected "Add new custom model". Fill in the model name (such as meta-llama-3.1-8b-instruct) and base URL. For LM Studio that's http://localhost:1234, and for Ollama that's http://localhost:11434.
I've tested a few models and would suggest using something in the 7–8B parameter range or larger if your Mac can handle it. Qwen 2.5 Coder has been working well for me on my 5 year old M1 iMac. I also recommend reducing the context length for speed. Around 1000 tokens works well. In LM Studio, you can do this by selecting the model in the main model list, clicking the cog settings button, and adjusting the "Context Length" parameter. I wouldn't recommend reasoning models such as DeepSeek R1, since the reasoning prevents Substage from feeling snappy, and I don't believe the thinking time helps, especially.
If you'd rather not mess with separate tools, I’m considering building in a simple way to download and use recommended models straight from the app. If that sounds good, let me know.
Behind the scenes
This release needed a fair bit of reworking under the hood—especially to support local models cleanly.
Prompting had to be redesigned. Previously, Substage used a long example-laden prompt to teach the model how to behave. That was fine for big cloud models, but local ones couldn’t handle the length. So now, prompts include just a few targeted examples, chosen dynamically based on what you type and what kind of files you’ve selected. If you ask it to convert a video to mp4, for instance, Substage quietly drops in an ffmpeg example behind the scenes. It’s faster, leaner, and still accurate.
I also had to rethink risk assessment for local LLMs. Cloud models analyse risk as they generate the command, using a custom format I specify. Local models couldn’t stick to the format reliably, so I added a new “Fast Mode” option for custom models which ONLY outputs the Terminal command, and we use a new hand-coded method to do risk assessment instead.
The new risk assessment checks for the existence of numerous tool usages in certain patterns. For example, if the command includes something like rm, it's flagged high risk; if it’s something harmless like echo, it’s low. It's never going to be absolutely bulletproof though; and you can still require confirmation every time if you prefer.
That's it! Let me know what you think:
- Join the Discord
- Request a feature
- Message me on Mastodon or Bluesky
- Sign up for email updates